Research Areas
12 core research areas driving innovation in bioinformatics and computational biology

Core Research Areas
Our program integrates computational and biological expertise across 12 specialized research domains, so students can pursue research in their area of interest.

Agricultural and Plant Bioinformatics
Computational analysis of plant genomes, transcriptomes, and metabolomes to support crop improvement, stress tolerance, and the study of phytonutrients and bioactive compounds

Drug Discovery and Pharmacogenomics
In silico methods for identifying, screening, and optimizing drug candidates including virtual screening, QSAR modeling, and pharmacogenomics

Evolutionary and Phylogenetic Analysis
Computational reconstruction of evolutionary relationships through molecular phylogenetics, phylogenomics, and molecular evolution analysis
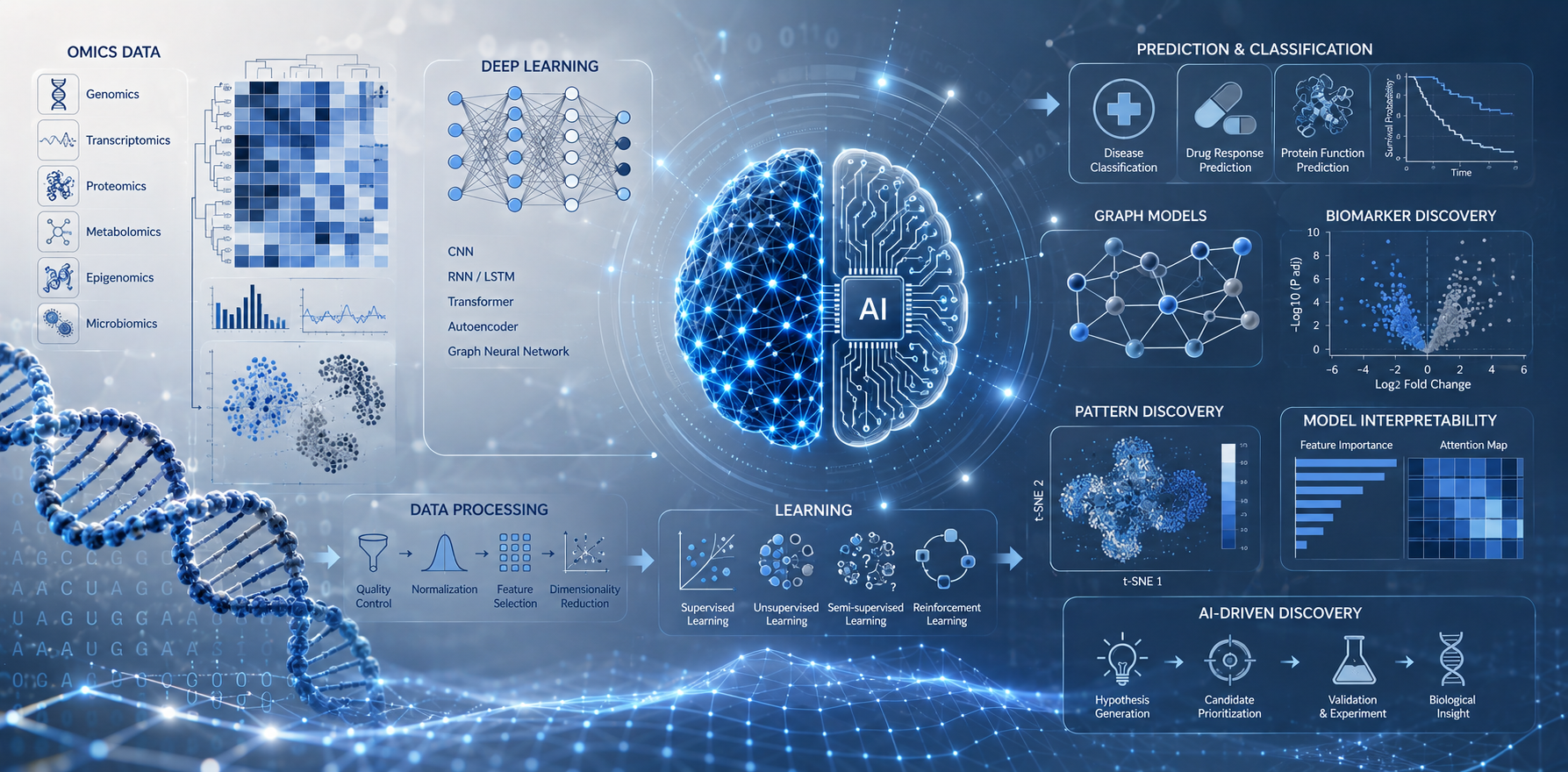
Machine Learning and AI in Biology
Application of deep learning, neural networks, graph models, and AI methods to predict biological properties, classify diseases, and discover patterns in omics data
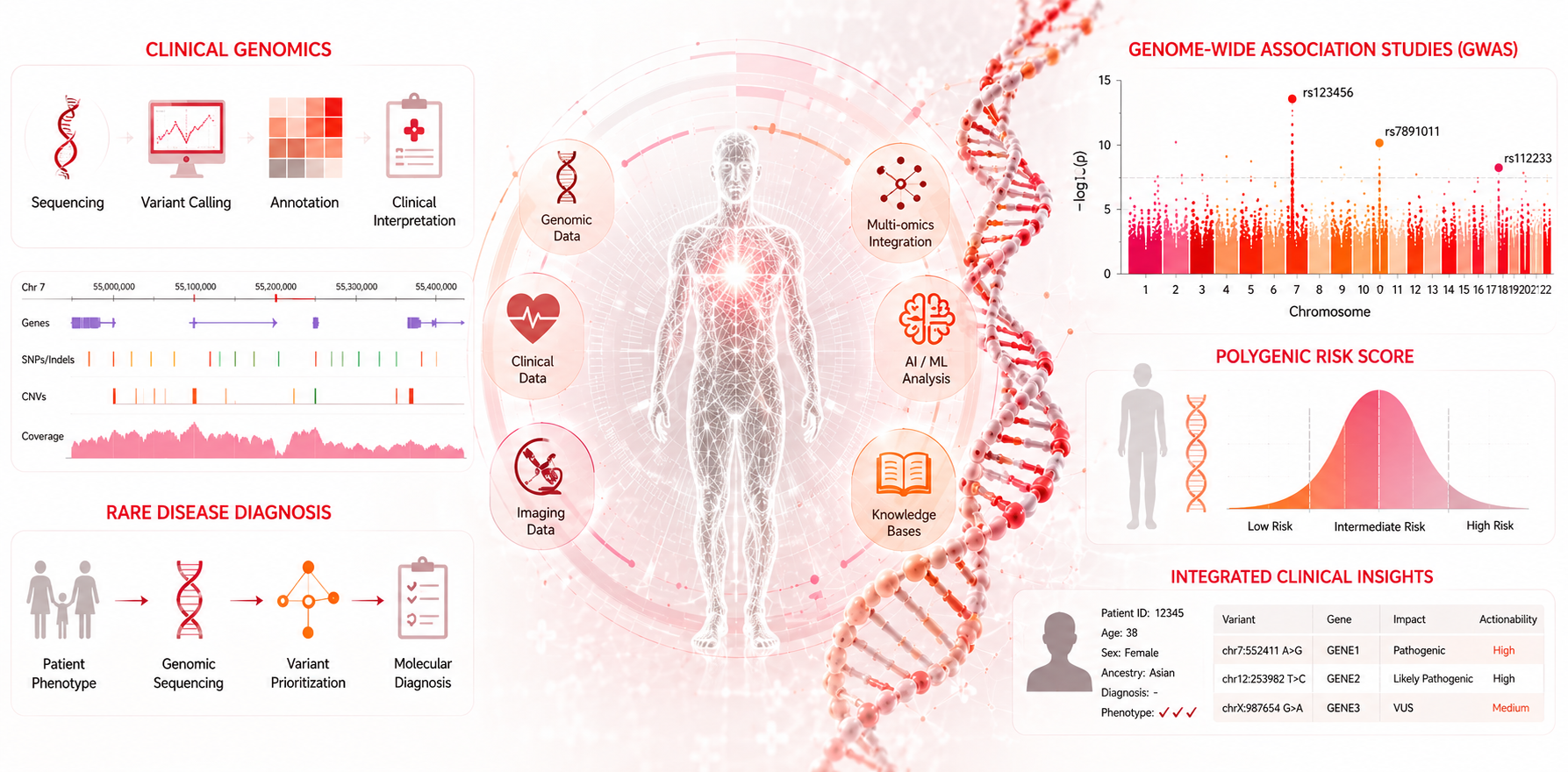
Medical and Clinical Bioinformatics
Application of bioinformatics to clinical genomics, rare disease diagnosis, genome-wide association studies, and precision medicine

Microbiome and Metagenomics
Analysis of microbiome composition and metagenomic data from environmental or clinical samples using 16S rRNA profiling and whole-metagenome shotgun sequencing

Proteomics and Metabolomics
Mass spectrometry-based computational approaches for large-scale identification, quantification, and functional characterization of proteins and metabolites

Sequence Analysis and Genomics
Comprehensive computational approaches to analyze DNA, RNA, and protein sequences, including whole-genome sequencing, variant calling, and comparative genomics

Single-Cell Omics and Multi-Omics Integration
Computational methods for analyzing single-cell RNA sequencing and integrating multi-omics data to resolve cellular heterogeneity, identify cell types, and study developmental trajectories
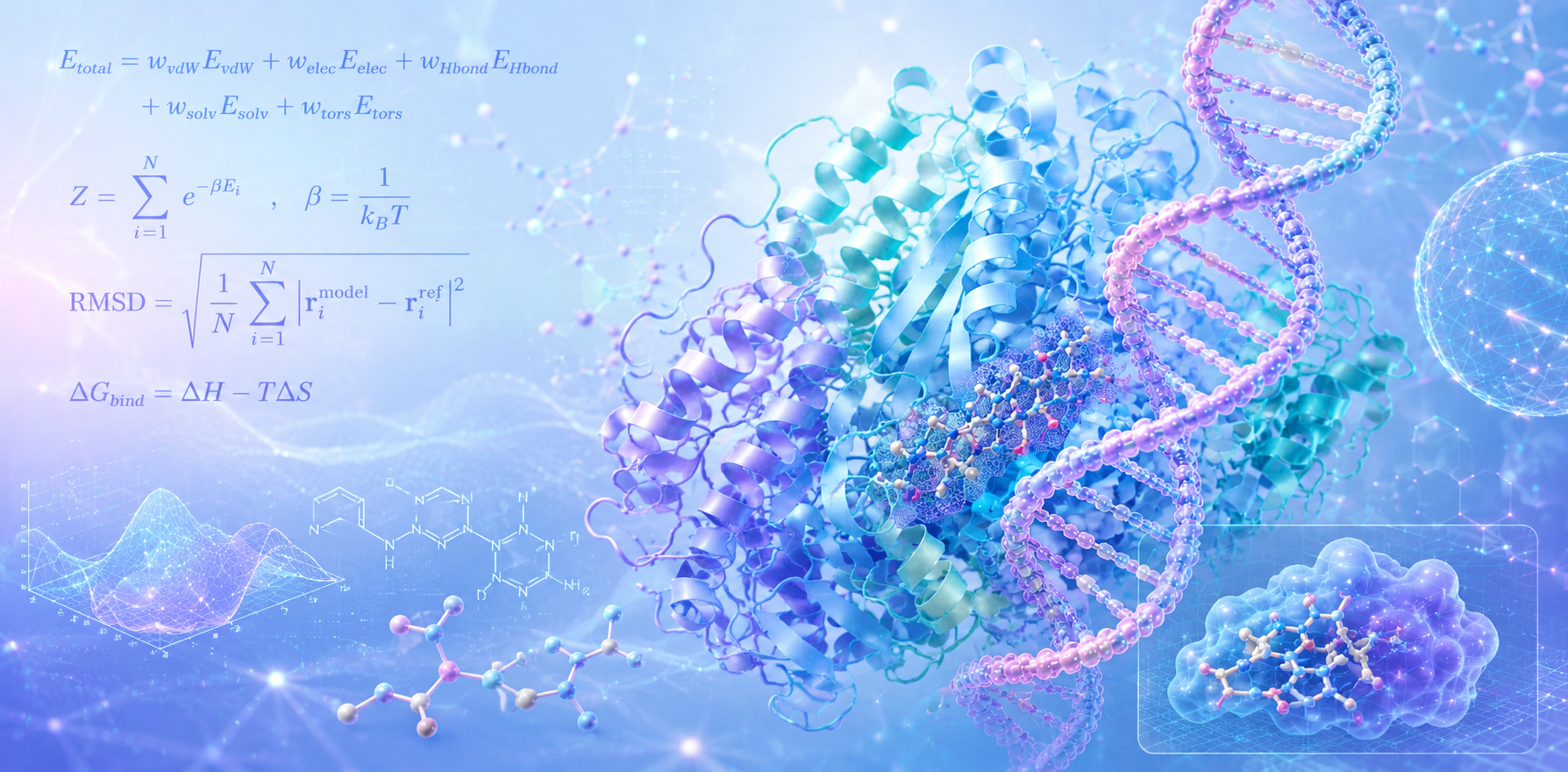
Structural Bioinformatics
Prediction, analysis, and simulation of three-dimensional protein and RNA structures to understand molecular function, interactions, and drug targets
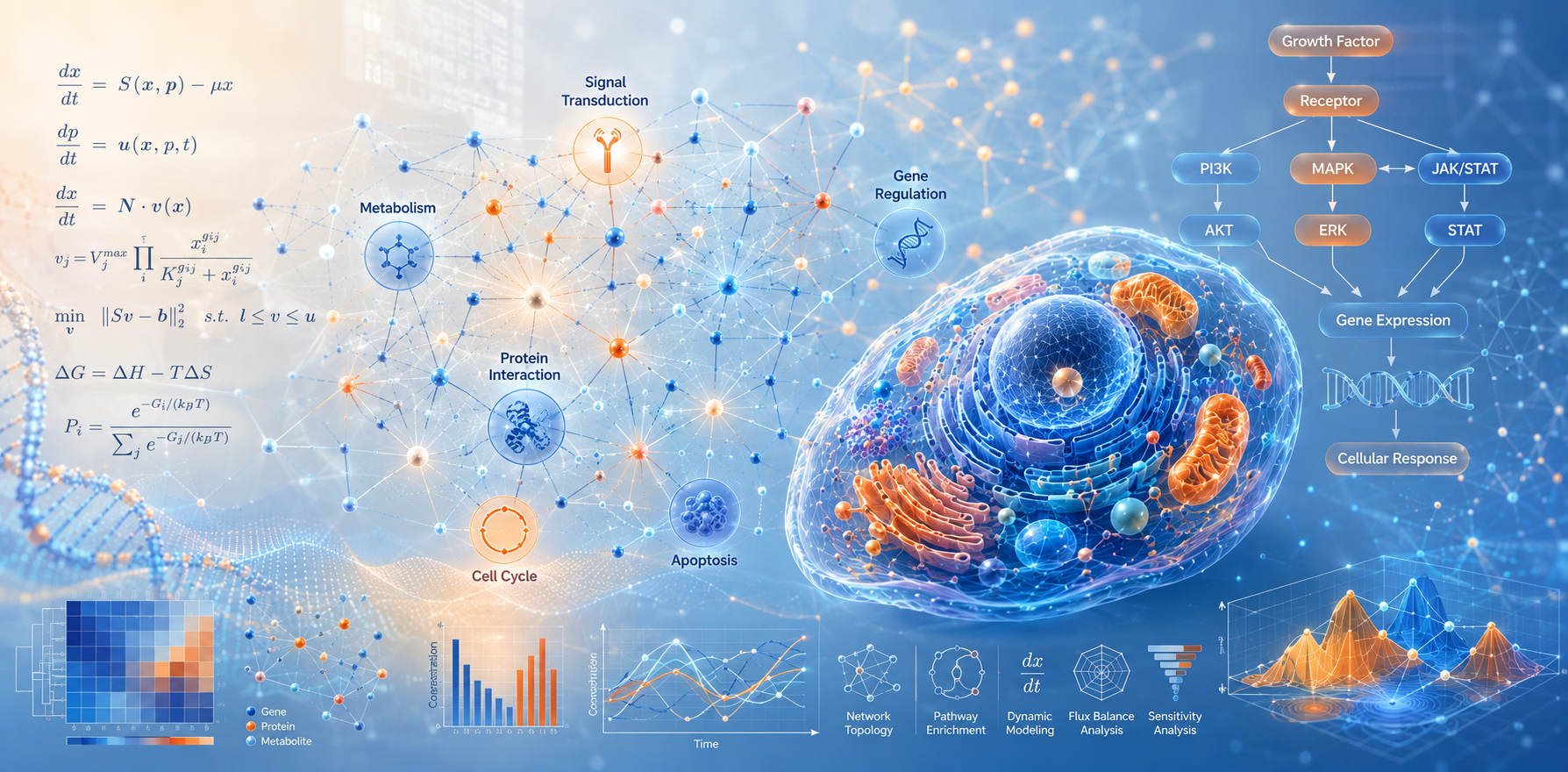
Systems Biology and Networks
Mathematical and computational modeling of biological networks and pathways to understand complex cellular behavior and emergent system properties
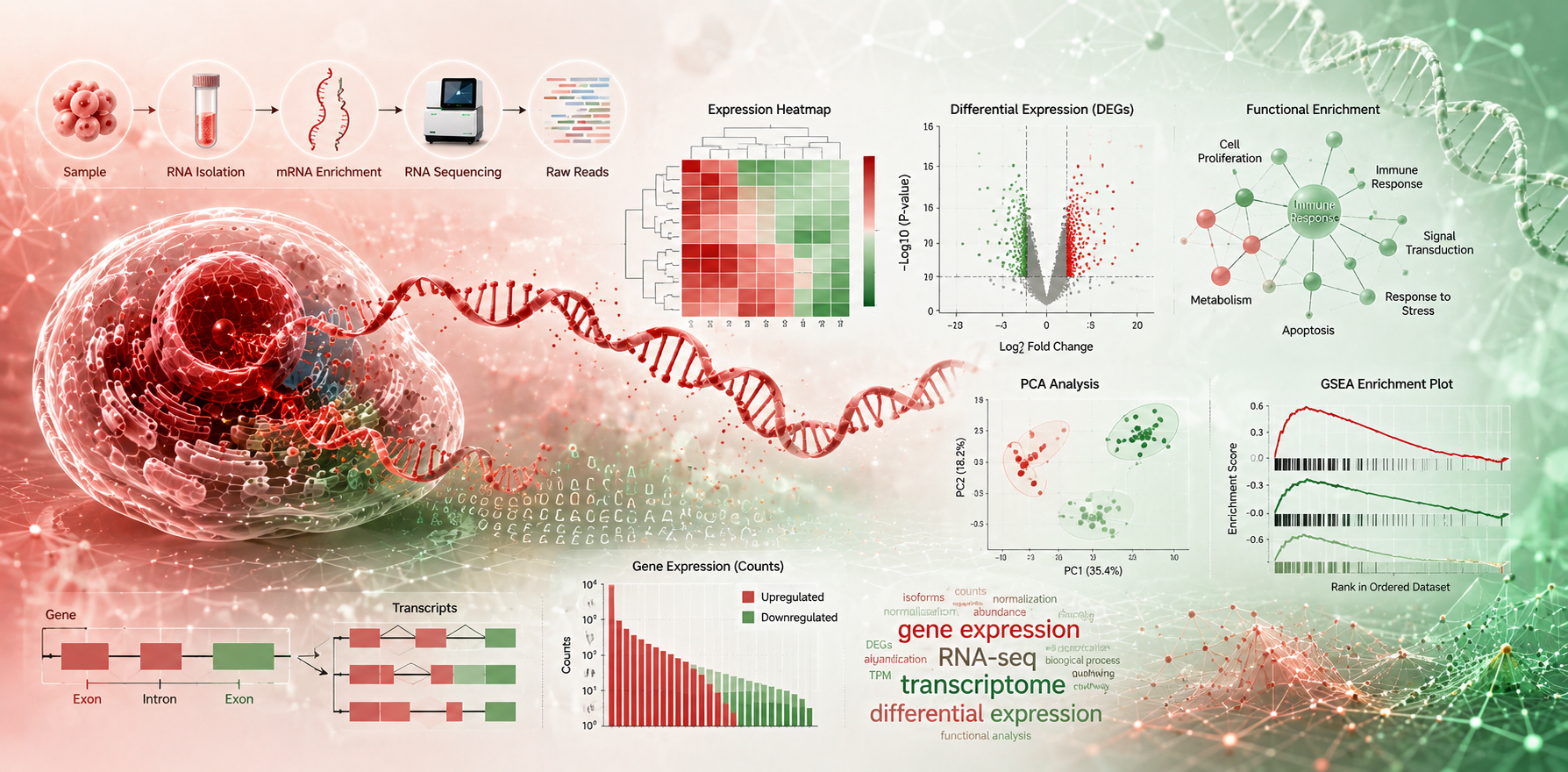
Transcriptomics and Gene Expression
Computational analysis of RNA sequencing data to quantify gene expression, identify differentially expressed genes, and characterize the transcriptome
Research Applications
These research areas drive real-world impact across five major application domains